„Онтотекст“ представи възможностите на отворените данни (Open Data) на среща в София
Българската софтуерна компания „Онтотекст“ АД представи възможностите на отворените данни в рамките на третата софийска среща, посветена на отворените и свързаните данни (Open Data and Linked Data). Събитието, което се проведе на 16 юни в Академията на Телерик, беше организирано от Sofia Open Data & Linked Data Group – неформална организация имаща за цел популяризирането на отворени и свързани данни (Open Data / Linked Data), заедно със Data Science Society – неформална българска организация, посветена на развитието на науката за данните и подкрепата на споделянето на знание, образованието и бизнеса в тази сфера.
Отворените данни представляват концепция за масиви от данни, които са публично достъпни и могат да бъдат използвани от всеки желаещ. Днес този подход се използва все по-често за създаването на нови платформи в областта на градоустройството, икономиката, науката, културното наследство, различни географски системи и др. В различни градове по света платформите за отворени данни позволяват оптимизиране на градския транспорт, прогнозиране на потенциални проблеми като честотата на извършване на престъпления или на пожари, замърсяването на въздуха и др. Като един от водещите разработчици на семантични технологии в света „Онтотекст“ работи по редица проекти, включващи отворени данни. „Онтотекст“ е част от групата на „Сирма Груп Холдинг“ АД, която планира скорошно първоначално публично предлагане (IPO) на Българската фондова борса (БФБ-София).
По време на събитието Димитрис Контокостас, който е главен технически директор на Асоциацията DBpedia и изследовател в един от най-големите в света изследователски центрове за сцързани данни – Agile Knowledge & Semantic Web Group (част от университета в Лайпциг), разказа как е създаден международният проект за извличане на структурирани отворени данни от Wikipedia – dbpedia.org и представи актуалните тенденции в сферата на свързаните и отворени данни. Проектът, който съществува от 2007 г., позволява извличане на данни от Wikipedia и използването им за отговор на комплексни въпроси като например: „Кои са всички футболисти, които са играли на позицията вратар, за клубове със стадион с над 40 000 места и които са родени в страна с над 10 милиона души население?“. Към момента платформата има локализирани версии на 125 езика и предоставя данни за почти 40 милиона обекта (хора, организации, географски локации).
Владимир Алексиев, главен експерт в „Онтотекст“ в сферата на онтологичния инженеринг и свързаните отворени данни представи в рамките на срещата развитието на българската версия на DBpedia – bg.dbpedia.org, която работи у нас от малко повече от година. Към декември 2014 г. тя включва 12 853 939 факти, 272 600 страници с информация, както и данни за 34 800 хора, 5700 организации и 15 621 места. В рамките на презентацията си Алексиев обясни, че в момента се търсят и ентусиасти, които имат желание да работят по неговото подобряване.
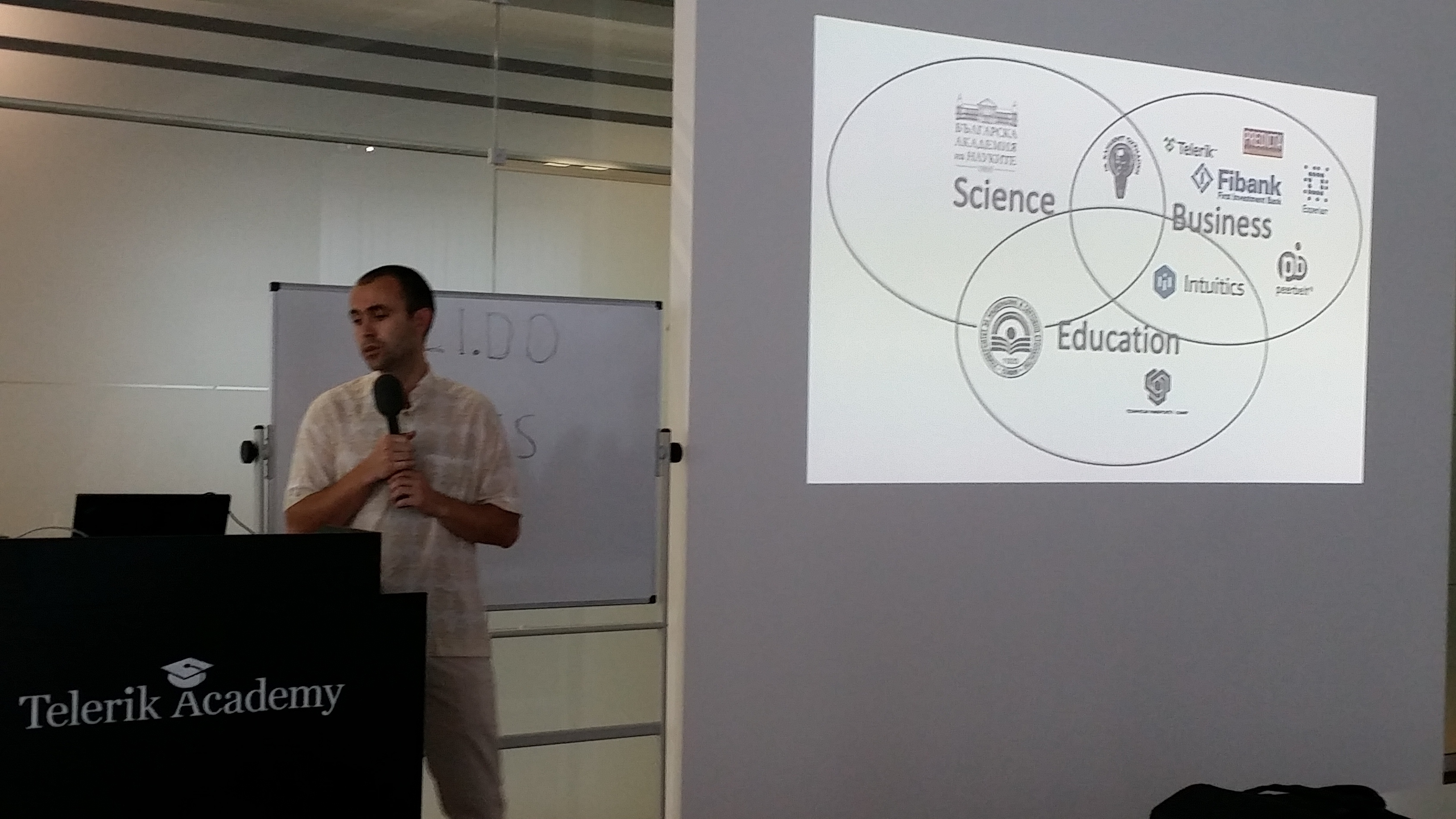
Серги Сергиев, един от основателите на Data Science Society, от своя страна представи организацията, която е единствената у нас, фокусирана върху развитието на иновативни технологии като Deep Learning, Natural Language Processing, Machine Learning for Music, Computer Vision и др. Създадена преди около година, тя стимулира сътрудничество между науката, бизнеса и образованието с цел споделяне на знание в сферата на отворените данни, популяризирането на този сегмент, откриването на възможности за бизнес и за обществени проекти в него. Проектите на организацията са насочени към анализ на данни от образователната сфера, медийния бранш, създаването на библиотеки с отворен код и др.





